Hello, and welcome back to the seventh entry of the apriori@home project development blog series! Earlier today, I posted an update regarding the work generator. Go back and read that post if you haven’t already, as this entry is a direct continuance.
So, now that we’re done with the work generator, and we have work units being created and processed by clients, what now? Well, we get an output file for each work unit processed thanks to the generate_candidates application, and currently, they live in a folder on the root directory named generate_candidates_results. Now, what can we do with these files? We’ve completed the first half of the Apriori algorithm by generating candidate sets, so now, we must complete the second half of the algorithm by finding out which candidates are frequent enough in the transactions list for them to be considered a significant finding.
This calls for another application! Similar to the generate_candidates application, I’ve developed calculate_frequency and registered it with our BOINC instance. You can find the source code for this application on this project’s GitHub page. Creating a new application means creating a new validator and assimilator, which I’ve also gone ahead and done.
A quick guide on what this application does: given a list of transactions and one output file from the generate_candidates application, scan the transactions and count how many times that the candidate set is a subset of the item set for a particular transaction. If the number of occurrences is above a certain threshold, we count that candidate as significant. If not, we can discard that candidate for the next candidate generation step, which is called purging.
Let’s go ahead and run the calculate_frequency application manually by staging one of the output files from the batch work units. We can do this by running the command:
bin/stage_file --copy --verbose generate_candidates_results/candidates_1 && \\
bin/create_work --appname calculate_frequency --command_line "-t 30 -tr transactions.dat in out" candidates_1 transactions.dat
This will stage one of our output files for download by BOINC clients, then create a single work unit of the calculate_frequency application using that file alongside the transactional database that we’ve been using for testing.
Here’s what a (truncated) typical output looks like:
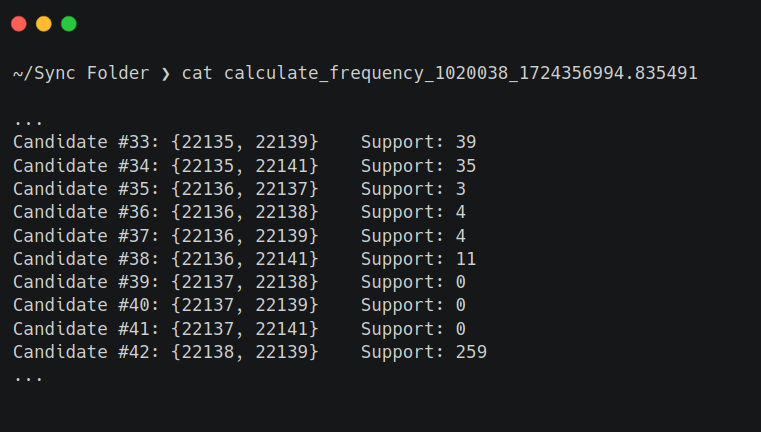
And with that, we’ve completed the Apriori algorithm for this specific subset of items at $k=2$–how exciting! What do these results mean though? As you can see, it looks like we have a result, Candidate #42, that has a support of 259 for item IDs $\\\{22138, 22139\\\}$. Looking this up in the Excel spreadsheet where the original transactional database was recorded, we can see that the two items are listed as “BAKING SET 9 PIECE RETROSPOT” and “RETROSPOT TEA SET CERAMIC 11 PC” respectively.
Off the bat, I can think of a few reasons these items might be purchased together frequently–they’re from the same RETROSPOT brand, they’re both sets of common kitchenware, they might come at a discount if you buy the two together, or maybe they’re placed right next to each other on the shelves. Speculation aside, it would definitely be a useful piece of data for a store manager to know that those two items are frequently bought together.
So now that we’ve completed an iteration of the algorithm, what’s next? Well, ideally, we could create another work generator to dynamically create work units for each output file from the candidate generation stage, and then re-feed the results of frequency calculation back into another round of candidate generation at a higher k-level. In English–now that we know that the baking set and tea set are bought together, we can try matching them up with all combinations of a third item and see if any of those item sets are frequently purchased, giving us another relation to study.
However, for now, I’ll be wrapping up this blog entry. As we’re nearing the end of the summer and my next academic semester soon approaches, it looks like my time with this project is coming to a end for now–so, thank you for reading! Please stay tuned, as in the next (final?) update, I’ll be giving a short conclusion on the project containing my thoughts and findings.
