Hello, and welcome back to the sixth entry of the apriori@home project development blog series! This week, I’ll be sharing some updates about progress regarding the work generator program.
For starters–let’s talk on a high level about what a work generator is. In the last update, I detailed generate_candidates_boinc, a C++ program that I’ve registered as a BOINC application in the apriori@home instance. Essentially what this program does is take a input file, run an algorithm to generate the potential candidates for the input items, and saves the results to an output file. Which is great, and what we want it to do, but it only does one file at a time.
This is where “work generators” come in. A work generator is responsible for taking a single input/multiple inputs, splitting/combining those inputs into evenly partitioned data sets, and then creating a work unit for a given application for each section of the data.
For our project, we’re gonna need a work generator that will take in one list of transactions, generate a set of unique items from the transactions, split that item list into manageable pieces, and run the generate_candidates application for each input file it creates.
To get started, I created a new C++ file to hold the code for the work generator. The first thing that needs to be done is take the transactions.dat file from the sample dataset that I’m using (which you can find here) and parse it to create a list of transactions. After parsing, a list of unique items will be created.
I’ve created a command line option for the work generator to input the “chunk size”, or, the number of items that the work generator will put into each input file. Right now I have this number set to 10, for no other reason than I think that work units generated with a chunk size of 5 took too short of a time and 15 took too long (very scientific, I know). Anyways, the list of unique items gets saved into a folder based on the UNIX timestamp, divided into multiple files based on the chunk size.
Now that we have a list of files containing a subset of our list of unique items, we can iterate over all of the files in the directory and use the BOINC API functions provided to us, such as create_work, in order to schedule a task of the generate_candidates application for each file. Which is what I would do, if I could get the linker to properly identify the database commands included in the boinc_db headers. I struggled with building the libraries properly for a while before ultimately deciding to go with a more traditional approach with exec().
The entirety of the code for the work generation is available on my GitHub repository for this project, so I won’t be going through all of it, but I think it’s important to go over the process forking part since it’s deviated from the intended work generation solution.
for (auto &itemFile : itemDirectory)
{
if (itemFile.is_regular_file())
{
// Fork the process
pid_t pid = fork();
std::string inputFile = itemFile.path().filename().c_str();
if (pid == 0) // Child process
{
// Change the current working directory to the project location.
std::filesystem::current_path(APRIORI_PROJECT_DIR);
// Exec create_work script
execl(CREATE_WORK, CREATE_WORK, "--appname", "generate_candidates", "--command_line", "-k 1 in out", inputFile.c_str(), nullptr);
// Following code is only reached if the execl fails for whatever reason.
std::cerr << "Failed to execute script for file: " << inputFile.c_str() << std::endl;
exit(1);
}
else if (pid > 0) // Parent process
{
// Wait for the child to finish executing--this is to prevent SQL db flooding
waitpid(pid, &status, 0);
}
else if (pid < 0) // Fork failure
{
std::cerr << "Failed to fork process for file: " << inputFile.c_str() << std::endl;
exit(1);
}
}
}
In a nutshell, for each file that exists in the directory we created, a fork of the currently running program is created. For all children processes created this way, we use the execl() C function in order to overwrite the current instructions with a bash command featuring additional command line parameters. In our case, we run the “CREATE_WORK” script provided in the server installation of BOINC. We pass it information based on which application we want it to run (generate_candidates) and information about the file that we’re currently on in the iteration.
For the original, non-forked parent process, we go ahead and wait for the child process to finish running so that we do not flood the SQL db with read/write calls through the work creation script (which was a pain to clean up the first time I accidentally ran it without this protection).
So, with that, some tweaking, and cleanup, we can run the work generation program and see that a work unit does get created for each file!
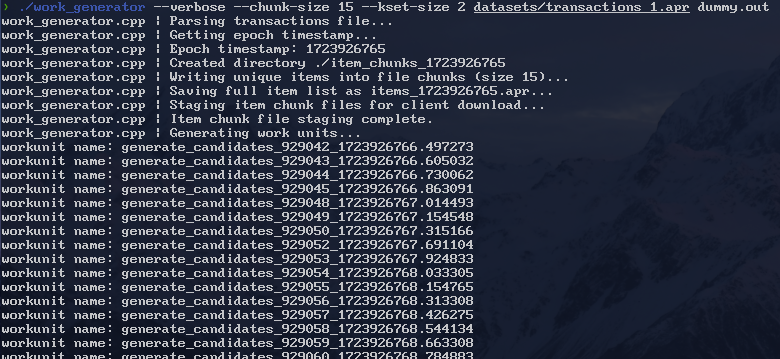
And we can check the admin panel on the website to see that the work units have been properly registered with BOINC:
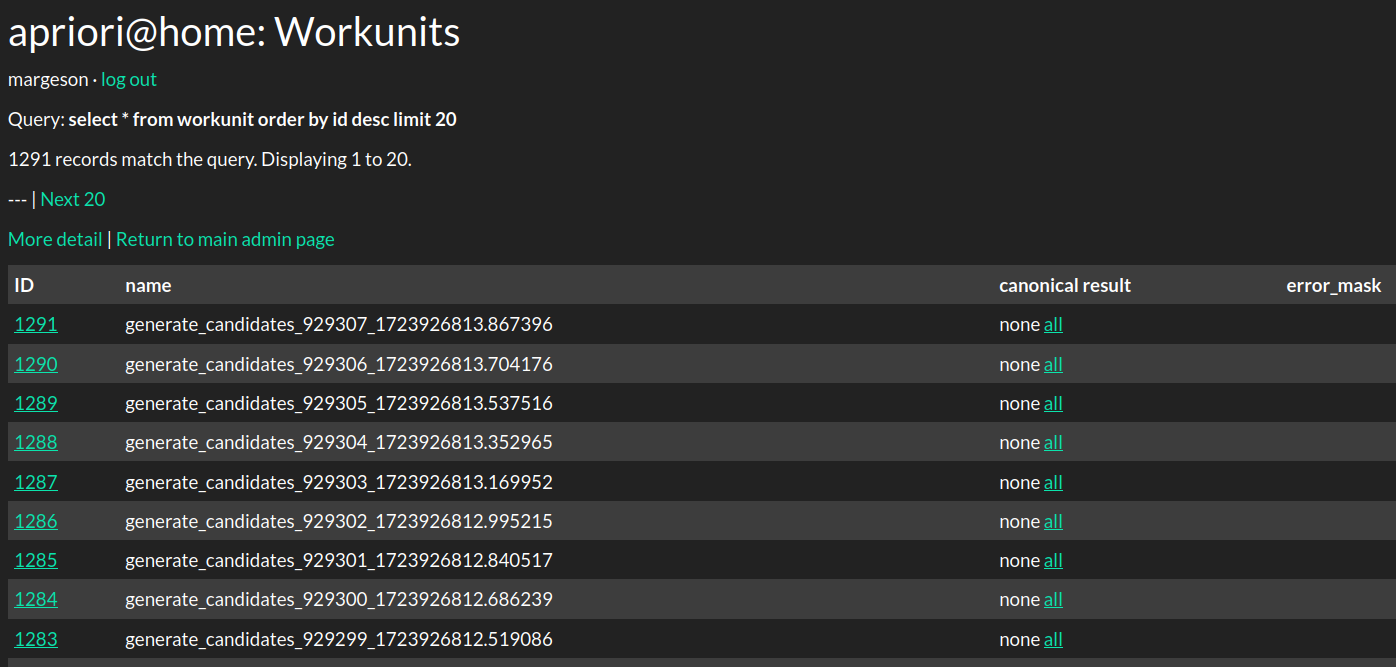
So, now that work generation is available, what’s next? Well, we’ve completed the first half of the Apriori algorithm. The next part is to take the candidate lists that were generated and calculate the frequency of those sets within our list of transactions. We’re gonna need another application to do this–and I’ve gone ahead and written one!
However, this post has gone on for a while, so I think I will go ahead and split this entry into two, and explain the workings of this new application in the next update. Thank you for reading! Please stay tuned, as next time, I’ll be going over how we’re gonna be finding frequency within our candidates.
